How many times a day do we search the Web? 10, 20 or maybe 50?
Although we may not pay much attention to them, search engines have become a crucial aspect of our daily lives.
They serve us in various places, from Google search engine to travel meta search engines and e-commerce sites.
In today’s guide, we will take a closer look at the inner workings of these systems and see what it takes to build your own custom search engine.
A search engine is a software application designed to help users find information on the Internet.
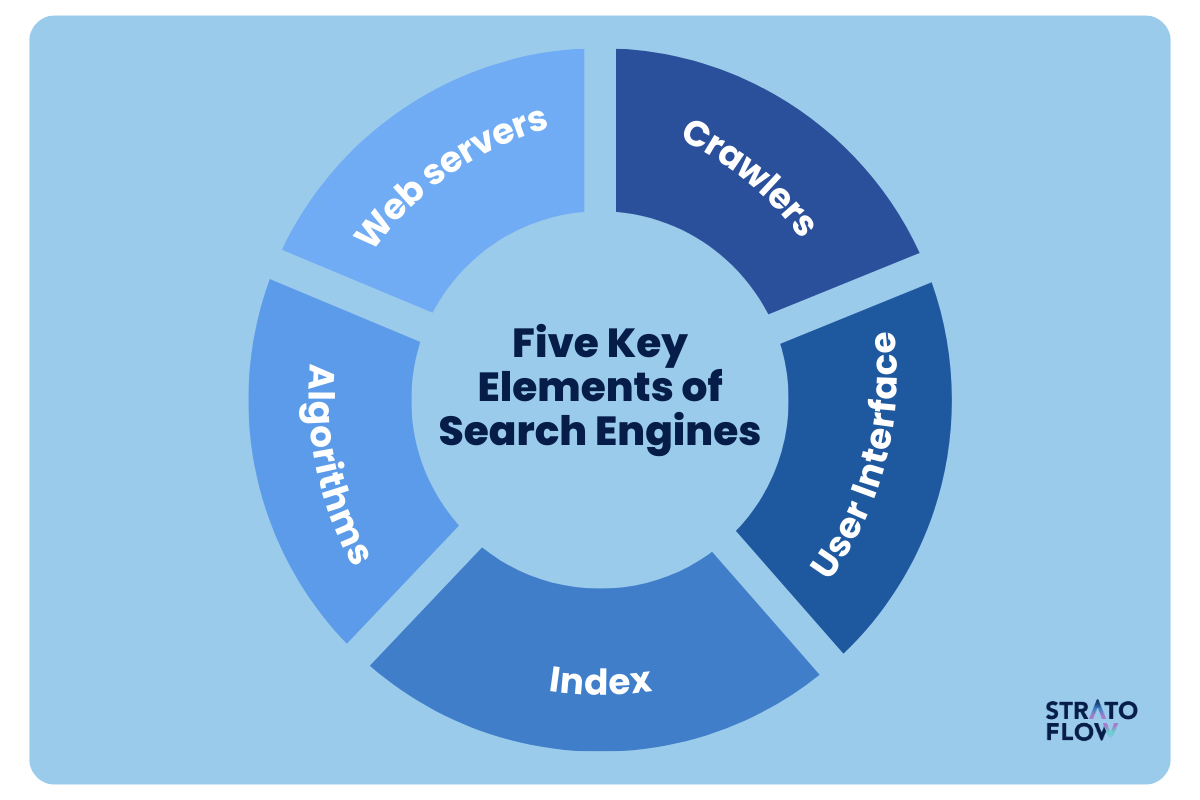
It uses algorithms to search the Internet based on keywords or phrases provided by the user and returns a list of results, typically in the form of web pages, that are most relevant to the user’s query. There are generally three key elements that go into any search engine:
Algorithms are critical for accurately processing and ranking vast amounts of data to ensure relevant and timely responses to user queries. The availability of rich data ensures that the search engine can comprehensively address a wide range of user queries.
Meanwhile, a customized cloud-based infrastructure provides the scalability and flexibility needed to ensure optimal data management, storage, and processing capabilities.
Apart from basic search functionality modern search engines often include additional features aimed at improving user experience and sales such as:
Search engines like Google, Bing, and Yahoo have become integral tools for navigating the vast amount of information available on the internet, helping users to find the specific information they are looking for efficiently and effectively.
Google is rightly considered the mother of all search engines.
But in some situations, a simple Google search just isn’t enough. Sometimes users demand more detail than the SERPs of popular major search engines can provide.
That’s where specialized search engines come in.
Specialized search engines are platforms designed to provide search results from a specific segment or type of content, focusing on a particular topic, industry, or type of data, such as academic papers, legal documents, or medical resources. Unlike general search engines, they prioritize and index content related to the specialized domain, providing users with more targeted, relevant, and in-depth results related to their specific queries within that domain.
Here’s a collection of some of the examples of popular specialized search engines .
Flights and Travel
Finance
Education and research
Professional services
Some might say that the importance of search engines in 2024 is fading away. After all, we are living in the age of AI and Social Media behemoths.
But that’s not true.
According to the latest data, 53% of website traffic still results from organic searches and search engines still drive 300% more traffic to sites than social media. The global search engine market size was USD 167020 million in 2021 and is projected to reach USD 477029 million by 2031. I guess Google isn’t going anywhere anytime soon.
And what about of custom, specialized search engines?
According to the latest research custom search engines handle an estimated 63,000 search queries on average per second indicating their powerful software architectures. As of 2023, the search market is poised to undergo a massive shakeup due to the launch of several AI-powered search tools that enable users to search for information in a conversational setting. We will have yet to see the true results of this massive shift but in 2024 we are bound to see some major advancements in the area of AI in the search engine industry.
We use them every day to search the web, browse products in online stores, or browse social media applications, but we rarely think about their inner workings.
Yet they are often the backbone of so many applications. One of their most important functionalities.
So, how does a search engine work?
Here are five key components of modern search engines that allow them to sort through huge amounts of data and deliver relevant results to their users.

First, we will look at a preliminary step: understanding web servers.
They play a central role in the functionality of search engines, even though they are not a direct component of them.
A web server is a software application or hardware device that uses HTTP (Hypertext Transfer Protocol) and other protocols to respond to requests made over the World Wide Web. When a user enters a query into a search engine, the request is sent to the web server, which then retrieves the relevant data from the search engine’s index and returns it to the user in the form of a Search Engine Results Page (SERP).
Web servers must manage and process many requests simultaneously to ensure that users have fast and reliable access to the information they seek. They are also responsible for securing data transmissions, managing user traffic, and ensuring that the data delivered is properly formatted and accessible across different devices and browsers.

Even the most basic search engine must gather the data it needs to generate results.
That’s the job of crawling – gathering data about websites and their pages, such as content, images, and links.
Web crawlers, also known as spiders, are automated programs or scripts that methodically and automatically navigate either a single website or the entire web (depending on the type of search engine we’re building).
A web crawler visits a web page, “reads” and analyzes its content, and then follows the links on that page to discover additional pages. This process allows them to index a vast amount of different types of content, which is then stored in a database that forms the basis of the search engine’s index. The information collected by the crawlers is used to update the search engine’s index and ensure that it has the most current and relevant data.

Once the data is collected, it’s time to process and organize it, and that’s where the index comes in.
The index is a huge database where all the information collected by the crawlers is stored and organized. When a crawler visits a web page, it collects various types of data, such as text, URLs, page title images, and links, and sends this data back to the search engine, which then adds it to the index.
The index is designed to optimize the speed of data retrieval, ensuring that when a user makes a query, the search engine can quickly find the most relevant information.
The organization of the index is critical to providing accurate and efficient search results because it must manage and make sense of the vast amount of data collected from across the Web.

By now our search engine has collected, processed, and organized the key information about our content.
Now comes the time for the most important part – using all the data to generate meaningful results for each individual user.
Search algorithms are complex sets of rules and calculations used by search engines to determine the relevance and ranking of pages in their index in relation to a user’s query.
Different sites and engines will have different ranking algorithms. All of them take into account various factors, such as keyword density, site structure, link quality, and user experience, to evaluate and rank webpages. The goal is to provide the user with the most relevant and high-quality results for their search.
Search engines continuously refine and update their algorithms to improve the accuracy and quality of the search results, adapting to new types of content and user behaviors.

When our search results are ready, the system needs to present them to users in the most appealing and intuitive way.
The Search Engine Results Page, commonly referred to as the SERP, is the page that displays the results of a user’s search query.
It typically contains a list of web pages that are relevant to the user’s query, along with additional information such as snippets, images, and links to give the user a preview of the content on each page.
The SERP may also include advertisements, rich results (such as images, reviews, and additional details), and other specialized results (such as news, videos, and maps) to provide users with the most comprehensive and useful information. The design and functionality of the SERP is critical to the user experience, as it is the interface through which users interact with the search engine and navigate to other web pages.
As you can see, there is a lot going on in the background of any search engine, whether it is a smaller system serving a single e-commerce site or a huge behemoth like Google.
Keep in mind that the last two parts, content ranking and results generation, have to happen within milliseconds to ensure a sufficient user experience.
Building search engine software is a complex task that involves various technical and design considerations.
Below you can find our simplified five-step process to give you a basic understanding of how one might go about building their own search engine. Learn more about our custom search solutions.
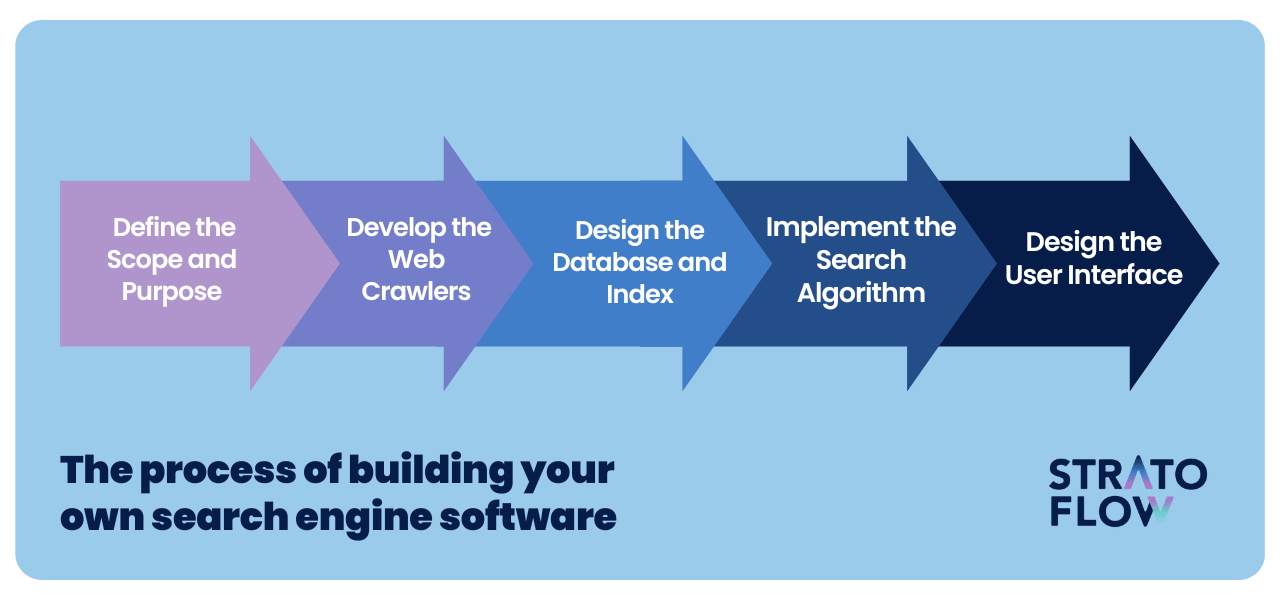

As with any software development project, building your own search engine should begin with defining the scope of the project and its desired functionality.
This includes identifying the primary goals, such as whether the engine will serve general search purposes, like Google, or serve a specialized niche, such as online travel agencies or e-commerce.
Understanding and defining the target audience is paramount, as it influences not only the software design and user interface, but also the underlying functionality and algorithms. This fundamental step ensures that subsequent development is focused on the intended purpose and adequately serves the user base.

Developing web crawlers, or spiders, is the next critical step in programming automated bots to navigate the web and collect relevant data.
Using programming languages such as Java and libraries and tools such as SpringBoot, Openkoda, Crawler4j, and Jsoup, developers create crawlers capable of collecting various types of data, including web page content, metadata, and links.
The crawling strategy must also be defined, determining the depth and breadth of crawling, such as whether to navigate only top-level pages or explore deeper into sub-pages to ensure comprehensive data collection.

The design and implementation of the database and index are critical to storing and efficiently retrieving the data collected by the crawlers.
Developers need to choose an appropriate database system. NoSQL database systems, such as Elasticsearch, may seem like the most obvious choice, but it should be based solely on the project’s requirements analysis.
The data must be structured and organized in a way that facilitates fast and accurate retrieval, which requires the creation of an index that effectively sorts and structures the data. Strategies for regularly refreshing and updating this data ensure that the search engine delivers current and relevant results.

Search algorithm implementation involves the development of computational rules and procedures to determine the relevance and ranking of pages in response to user queries.
This includes creating algorithms that evaluate page relevance based on various factors such as keyword matching and link analysis, and determining how results are ranked based on aspects such as keyword relevance, page quality, and user behavior.
In addition, developers can incorporate elements of personalization, tailoring search results based on user behavior, location, and other relevant factors to improve user experience and satisfaction.
At last we come to the user interface design – an integral part of providing an intuitive and user-friendly experience.
This step involves creating a design that is not only visually appealing, but also easy to use, considering aspects such as how search results are displayed and how users enter queries. Ensuring that the design is responsive and accessible across devices and screen sizes is critical to serving a broad user base.
Implementing mechanisms for user feedback, problem reporting, and search refinement allows the search engine to continually evolve and adapt to user needs and preferences, ensuring ongoing usability and relevance.
Building a search engine can be a complex and resource-intensive task, and the cost can vary widely based on the scope, features, and scale of the project. Here are some factors that can influence the cost of building custom software like a search engine:
Let’s face it – search engine development is no easy feat.
Unlike more straightforward programming projects, search engine development requires expertise in web crawling, data indexing, algorithm development, machine learning, and user interface design, among other areas.
Each of these areas presents its own set of challenges and complexities, making the overall task of building a search engine quite daunting.
The importance of developer experience cannot be overstated.
Developers with prior experience building search engines or similar technologies are likely to have encountered and overcome numerous challenges that can arise during the development process.
These include handling large amounts of data, ensuring efficient data retrieval, developing accurate and effective search algorithms, and creating a user-friendly interface. Specialized knowledge, particularly in areas such as natural language processing, machine learning, and data management, is also critical to developing a sophisticated and effective search engine. For example, implementing features such as semantic search, personalized results, or voice search requires a deep understanding of specific technologies and methodologies.
In summary, building a search engine is a meticulous amalgamation of sophisticated algorithms, data management, and user interface design, each of which plays a critical role in delivering accurate and relevant search results.
Hiring developers with the necessary experience and expertise is paramount to ensuring that the complexities of web crawling, data indexing, and algorithm development are handled with expertise and precision.
Ensuring continuous refinement and updates post-development will further enhance the search engine’s effectiveness and user satisfaction, solidifying its utility and reliability in the digital space.
Thank you for taking the time to read our blog post!